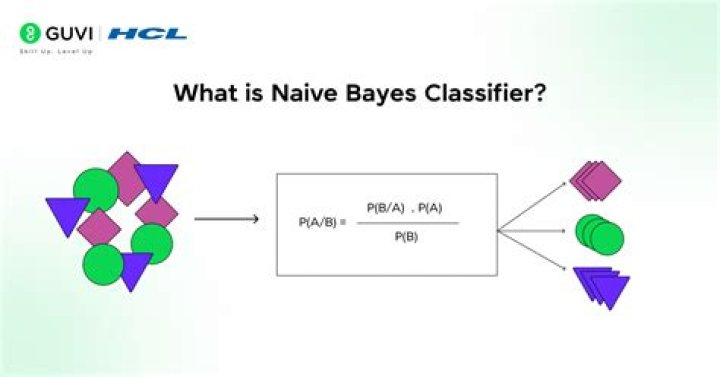
Naive Bayes uses a similar method to predict the probability of different class based on various attributes. This algorithm is mostly used in text classification and with problems having multiple classes.
What is the main idea of naive Bayesian classification?
A naive Bayes classifier assumes that the presence (or absence) of a particular feature of a class is unrelated to the presence (or absence) of any other feature, given the class variable. Basically, it’s “naive” because it makes assumptions that may or may not turn out to be correct.
What is the naive Bayes algorithm and where is it used in NLP?
Naive Bayes are mostly used in natural language processing (NLP) problems. Naive Bayes predict the tag of a text. They calculate the probability of each tag for a given text and then output the tag with the highest one.
What is the benefit of naive Bayes in machine learning?
Advantages. It is easy and fast to predict the class of the test data set. It also performs well in multi-class prediction. When assumption of independence holds, a Naive Bayes classifier performs better compare to other models like logistic regression and you need less training data.Where is naive Bayes used in machine learning?
Naive Bayes is a machine learning model that is used for large volumes of data, even if you are working with data that has millions of data records the recommended approach is Naive Bayes. It gives very good results when it comes to NLP tasks such as sentimental analysis.
How do you use naive Bayes?
- Step 1: Calculate the prior probability for given class labels.
- Step 2: Find Likelihood probability with each attribute for each class.
- Step 3: Put these value in Bayes Formula and calculate posterior probability.
What is naive in naive Bayes algorithm?
Naive Bayes is a simple and powerful algorithm for predictive modeling. … Naive Bayes is called naive because it assumes that each input variable is independent. This is a strong assumption and unrealistic for real data; however, the technique is very effective on a large range of complex problems.
What is Gaussian naive Bayes in machine learning?
Gaussian Naive Bayes is a variant of Naive Bayes that follows Gaussian normal distribution and supports continuous data. … Naive Bayes are a group of supervised machine learning classification algorithms based on the Bayes theorem. It is a simple classification technique, but has high functionality.Is naive Bayes good for NLP?
It has been successfully used for many purposes, but it works particularly well with natural language processing (NLP) problems. Naive Bayes is a family of probabilistic algorithms that take advantage of probability theory and Bayes’ Theorem to predict the tag of a text (like a piece of news or a customer review).
How do I use Naive Bayes classifier in Python?- Step 1: Separate By Class.
- Step 2: Summarize Dataset.
- Step 3: Summarize Data By Class.
- Step 4: Gaussian Probability Density Function.
- Step 5: Class Probabilities.
Why multinomial naive Bayes is used in text classification?
Multinomial Naive Bayes classifiers has been used widely in NLP problems compared to the other Machine Learning algorithms, such as SVM and neural network because of its fast learning rate and easy design. In text classification these are giving more accuracy rate despite their strong naive assumption.
Is naive Bayes classification or regression?
Naïve Bayes is a classification method based on Bayes’ theorem that derives the probability of the given feature vector being associated with a label. … Logistic regression is a linear classification method that learns the probability of a sample belonging to a certain class.
What is SVM in deep learning?
“Support Vector Machine” (SVM) is a supervised machine learning algorithm that can be used for both classification or regression challenges. … Support Vectors are simply the coordinates of individual observation. The SVM classifier is a frontier that best segregates the two classes (hyper-plane/ line).
Why is Naive Bayes good for high dimensional data?
Because of the class independence assumption, naive Bayes classifiers can quickly learn to use high dimensional features with limited training data compared to more sophisticated methods. This can be useful in situations where the dataset is small compared to the number of features, such as images or texts.
How does a naïve Bayes classifier help in classifying the output class?
Naive Bayes classifiers are a collection of classification algorithms based on Bayes’ Theorem. It is not a single algorithm but a family of algorithms where all of them share a common principle, i.e. every pair of features being classified is independent of each other.
When should we use multinomial Naive Bayes?
The multinomial Naive Bayes classifier is suitable for classification with discrete features (e.g., word counts for text classification). The multinomial distribution normally requires integer feature counts. However, in practice, fractional counts such as tf-idf may also work.
How does multinomial naive Bayes algorithm work?
Multinomial Naïve Bayes uses term frequency i.e. the number of times a given term appears in a document. Term frequency is often normalized by dividing the raw term frequency by the document length.
How does Laplace smoothing work?
Laplace smoothing is a smoothing technique that helps tackle the problem of zero probability in the Naïve Bayes machine learning algorithm. Using higher alpha values will push the likelihood towards a value of 0.5, i.e., the probability of a word equal to 0.5 for both the positive and negative reviews.
Can naive Bayes used for regression?
Naive Bayes classifier (Russell, & Norvig, 1995) is another feature-based supervised learning algorithm. It was originally intended to be used for classification tasks, but with some modifications it can be used for regression as well (Frank, Trigg, Holmes, & Witten, 2000) .
What is SVM used for?
Support vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection. The advantages of support vector machines are: Effective in high dimensional spaces. Still effective in cases where number of dimensions is greater than the number of samples.
How SVM is used for classification?
SVM is a supervised machine learning algorithm which can be used for classification or regression problems. It uses a technique called the kernel trick to transform your data and then based on these transformations it finds an optimal boundary between the possible outputs.
What is the objective of SVM algorithm?
The objective of SVM algorithm is to find a hyperplane in an N-dimensional space that distinctly classifies the data points. The dimension of the hyperplane depends upon the number of features. If the number of input features is two, then the hyperplane is just a line.